大数据入门
felix9ia ... 2022-8-4 大约 6 分钟
# 大数据入门
# 大数据术语
参考大数据正当时,理解这几个术语很重要 (opens new window)
01 离线计算 Vs 实时计算
02 实时查询 Vs 即席查询
03 OLTP Vs OLAP
04 行式存储 Vs 列式存储

spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 1G --num-executors 3 --executor-memory 1G --executor-cores 1 /home/hadoop/spark-2.4.3-bin-without-hadoop/examples/jars/spark-examples_2.11-2.4.3.jar
1
之后可以看到:

如果内存过小,配置yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /input/input.txt /felixcountoutput
1
import logging
from operator import add
from pyspark import SparkConf, SparkContext
logging.basicConfig(format='%(message)s', level=logging.INFO)
input_file_name = "hdfs://localhost:9000/input/hadoop/yarn-site.xml"
out_file_name = "hdfs://localhost:9000/test/spark/data-output1.txt"
conf = SparkConf().setMaster("yarn").setAppName("Linkis-EngineConn-Spark_IDE")
sc = SparkContext.getOrCreate(conf = conf)
text_file = sc.textFile(input_file_name)
counts = text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word,1)).reduceByKey(lambda a,b:a+b)
counts.saveAsTextFile(out_file_name)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# OLTP
联机事务处理OLTP(on-line transaction processing),OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易
# 即席查询
即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的
# OLAP
联机分析处理OLAP(On-Line Analytical Processing), OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
# 数据仓库
ODS、DWD、DWM、DWS、ADS
详解数仓中的数据分层:ODS、DWD、DWM、DWS、ADS (opens new window)

# 工具入门
(1)HDFS集群:负责海量数据的存储,集群中的角色主要有 NameNode / DataNode/SecondaryNameNode。
(2)YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(3)MapReduce:它其实是一个应用程序开发包。
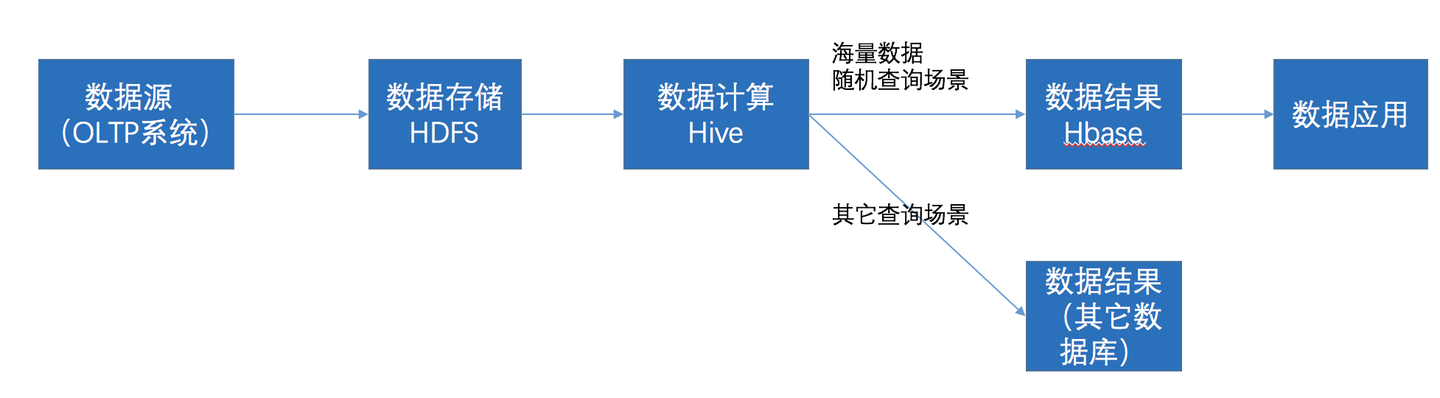
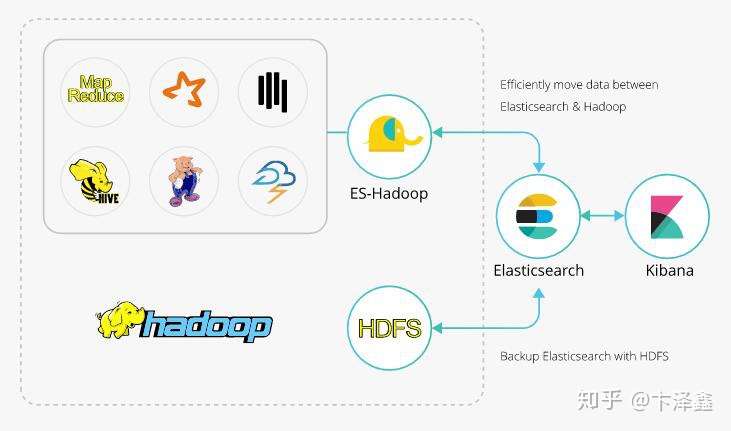
# ETL 工具
#
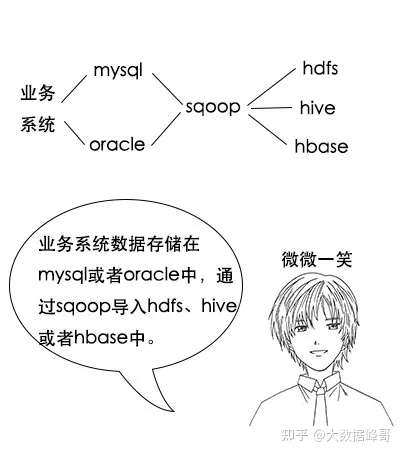
# 迁移工具
迁移工具就是将业务数据复制一份到大数据这边
# sqoop
# 时序数据库
关于时序数据库的对比 Druid vs. ClickHouse vs. InfluxDB (opens new window),
阿里巴巴双11千万级实时监控系统技术揭秘 (opens new window)
阿里云栖开发者沙龙(第六期)时序数据库专场 (opens new window)
各类数据库使用场景比较 (opens new window)
# 工具
# Hadoop
数据存储层:分布式文件存储系统 HDFS,分布式数据库存储 HBase
数据处理层:进行数据处理的 MapReduce,负责集群和资源管理的 YARN
数据访问层:Hive、Pig、Mahout
# Hive
HBase 和 Hive 的差别是什么,各自适用在什么场景中? (opens new window)
hive是文件的视图,HBASE就是架在Hadoop上的MongoDB,纯kv引擎,没有事务,row key级索引
Hive:Hive是Hadoop数据仓库 (opens new window),严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
# 优缺点
- 并发写入不高
- hive 查询不快
# 场景
离线数据分析
# HBase
Use Apache HBase™ when you need random, realtime read/write access to your Big Data.
hbase是建了索引的key-value表,HBASE就是架在Hadoop上的MongoDB,纯kv引擎,没有事务,row key级索引
Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
# Flink
是一种流式处理

# Spark
Spark 只能代替 Hadoop 的数据处理层的 MapReduce,其余还得依赖 Hadoop
操作如下
- Map
- Filter
- flatMap
- groupByKey
- Union
五个扩展库
- 支持结构化数据的 Spark SQL
- 处理实时数据的 Spark Streaming
- 用于机器学习的 MLlib
- 用于图计算的 GraphX
- 用于统计分析的 SparkR

RDD

RDD逻辑上是一个大数组,其特点是:
分区
分区是指存储在系统的不同节点,数组中的每个元素代表一个分区。分区内部不存储具体的数据

不可变的
并能够被并行操作
Spark术语01-application、job、Stage、task的区别 (opens new window)
job
stage
task
# Spark-streaming


DStream是spark-streaming提供的一个抽象数据类型, 就是按时间切分的一组有序RDD集合。
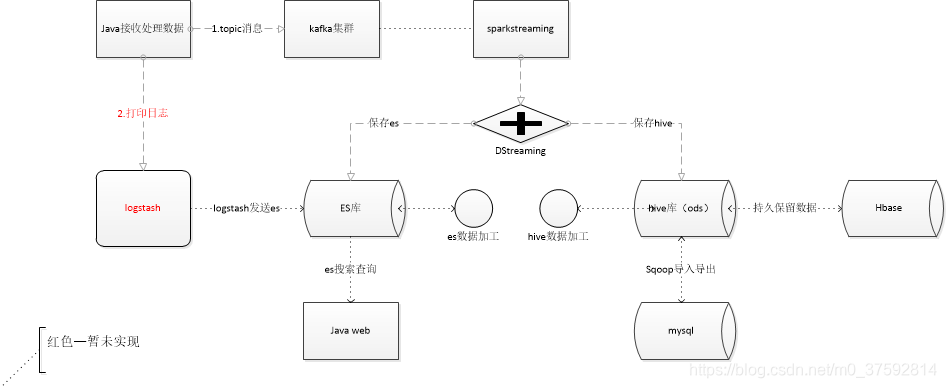

spark-submit --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties" --master local[2] --name xladata-clean --class ai.neuvision.sdk.neudataanalysis.streaming.clean.realtime.XlaDataToIndex ./NeuDataAnalysis-streaming.jar
1
spark-submit --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=file:log4j.properties" --master local[2] --name calldata-clean --class ai.neuvision.sdk.neudataanalysis.streaming.main.TestMain ./NeuDataAnalysis-streaming.jar

# Spark-SQL
# DSS
如果 8901 端口总是报错,接口报err_incomplete_chunked_encoding,是因为nginx需要写入缓存没有权限,需要执行sudo chown -R hadoop:hadoop /var/lib/nginx
# 批处理
批处理是为了有界离散的数据
hadoop(mapreduce)、hive 是批处理
Flink DataSet
# 流处理
流处理是为了无界连续的数据
Flink DataStream
Apache Kafka、Apache Flink、Apache Storm、Apache Samza 等,都是流行的流处理架构平台。
# 流批一体
未来主流
- Apache Flink
- Apache Bean
# workflow
复制模式
一个视频数据集被不同的模块同步进行处理
过滤模式
只处理满足条件的
分离模式
数据分组,会员等级
合并模式
将不同的数据合并起来之后再处理
# Lambda架构
- 批处理层
- 速度处理层
- 服务层

# Kappa 架构
依赖于 kafka
# 参考
Hive Tables (opens new window)
与 Hadoop 对比,如何看待 Spark 技术? (opens new window)
运行hadoop提供的示例程序 (opens new window)
使用Spring-hadoop小结 (opens new window)
Spark2.3.1中用各种模式来跑官方Demo (opens new window)
Submitting Applications (opens new window)
spark download and install, run the examples (spark a) (opens new window)
Linkis1.0.2 安装及使用指南 (opens new window)
如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系? (opens new window)
Spark Streaming 设计原理 (opens new window)
hbase宽表和高表以及优缺点 (opens new window)
有赞数据仓库实践之路,超全面干货! (opens new window)
Java Spark 简单示例(五)Spark Streaming (opens new window)
Kafka + Spark Streaming +Hive 数据采集入库整合实践(二) (opens new window)
Sparkstreaming读取kafka数据写入hive和es (opens new window)
使用docker搭建spark(2.3.1)集群 (opens new window)
Spark Streaming 编程入门指南 (opens new window)
infoq-硬刚 Apache Iceberg | 技术调研 & 在各大公司的实践应用大总结 (opens new window)
infoq-Spark 比拼 Flink:下一代大数据计算引擎之争,谁主沉浮? (opens new window)
【实时计算】Spark批处理流程图解 + 深入剖析 (opens new window)
什么是OLAP?主流八大开源OLAP技术架构对比 (opens new window)